AI 에이전트 기업 달파(Dalpha)가 시계열 예측과 딥리서치 분야의 글로벌 AI 벤치마크 3개에서 1위를 기록했다고 밝혔다. 회사 주장대로라면 구글, 오픈AI, 엔비디아, 알리바바 등 글로벌 빅테크와의 성능 경쟁에서 앞선 셈이다. 다만 벤치마크 성과와 별개로, 실제 산업 현장에서 얼마나 재현 가능한 성능을 보여주는지는 별도의 검증이 필요한 대목이다.
달파는 22일 자사 AI 에이전트 시스템이 글로벌 벤치마크 3개에서 최고 점수를 기록했다고 발표했다. 회사가 제시한 항목은 세일즈포스의 시계열 예측 평가 지표 ‘GIFT-Eval’, 연구형 AI 에이전트를 평가하는 ‘DeepResearch Bench’, 그리고 정밀 루브릭 기반 후속 지표인 ‘DeepResearch Bench II’다.
달파 설명을 종합하면, 먼저 GIFT-Eval에서는 자사 에이전틱 시스템이 시계열 전용 모델들을 제치고 종합 1위에 올랐다. GIFT-Eval은 세일즈포스가 공개한 시계열 예측 평가 체계로, 28개 데이터셋과 14만개 이상 시계열 데이터를 기반으로 모델의 일반화 성능을 비교하는 벤치마크다. 시계열 예측은 시간 흐름에 따라 축적된 데이터를 분석해 수요와 재고, 물류, 마케팅 성과를 예측하는 기술로, 패션·뷰티·식음료(F&B) 같은 소비재 업종에서 특히 활용도가 높다.
달파는 여기서 데이터독, 세일즈포스 등 주요 기업이 시계열 예측용으로 개발한 파운데이션 모델보다 높은 종합 성적을 거뒀다고 밝혔다. 단일 태스크에 맞춘 전용 모델이 아니라, 자사 범용 AI 에이전트 프레임워크로 성능을 냈다는 점을 강조했다.
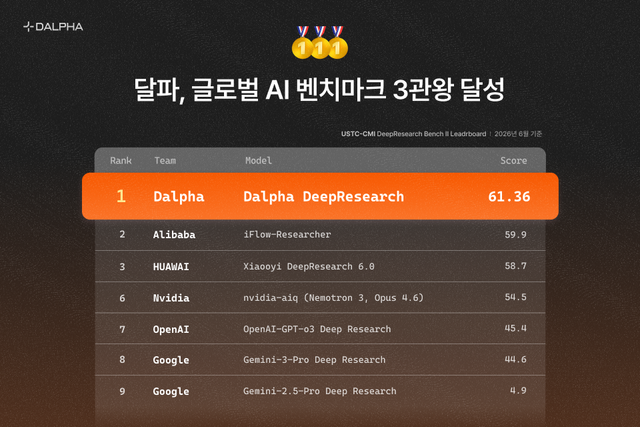
딥리서치 영역에서도 달파는 자신감을 드러냈다. 회사에 따르면 22개 도메인, 100개 박사급 연구 과제로 구성된 ‘DeepResearch Bench’에서 구글 제미나이, 오픈AI, 퍼플렉시티, xAI 그록 계열 딥리서치 시스템보다 높은 종합 점수를 기록했다. DeepResearch Bench는 웹 탐색, 자료 수집, 장문 리포트 작성 능력을 평가하기 위해 설계된 벤치마크로, AI 연구·산업계에서 ‘딥리서치 에이전트’ 성능을 가늠하는 대표 지표 가운데 하나로 꼽힌다. 관련 논문과 공개 자료에 따르면 이 벤치마크는 22개 분야, 100개의 고난도 연구 과제로 구성되며, 리포트 품질과 인용 정확도 등을 함께 평가한다.
달파는 여기서 한 발 더 나아가 후속 평가 체계인 ‘DeepResearch Bench II’에서도 1위를 차지했다고 밝혔다. DeepResearch Bench II는 132개 전문가 리포트에서 도출한 9430개 세부 루브릭을 바탕으로 정보 회수, 분석, 표현 능력을 촘촘하게 평가하는 방식이다. 공개된 논문과 저장소 설명을 보면, 기존 딥리서치 평가가 보고서 품질을 뭉뚱그려 점수화하는 한계를 보완하기 위해 보다 세분화된 검증 구조를 도입한 것이 특징이다.
달파는 이 정밀 평가에서 오픈AI, 구글, 엔비디아, 화웨이, 알리바바, 바이트댄스 등을 종합 점수에서 앞섰다고 설명했다. 또 지난 5월에는 오픈AI가 공개한 머신러닝 에이전트 평가 지표 ‘MLE-bench’에서도 자체 검증 기준 79.11% 점수를 기록해 구글과 바이두보다 높은 성과를 냈다고 덧붙였다. 다만 현재 공개된 MLE-bench 리더보드는 다양한 외부 연구팀과 에이전트가 경쟁하는 형태로 운영되고 있고, 제출 중단이나 평가 방식 변경 이력도 있어, 개별 기업이 발표한 수치를 외부에서 동일 조건으로 대조하려면 세부 제출 방식과 평가 설정까지 함께 확인할 필요가 있다.
이번 발표에서 달파가 특히 강조한 부분은 ‘범용 에이전트 프레임워크’다. 특정 과제 하나를 위해 만든 전용 모델이 아니라, 서로 성격이 다른 벤치마크에서 고르게 성능을 냈다는 점을 강점으로 내세웠다. 시계열 예측은 구조화된 수치 데이터를 다루는 영역에 가깝고, 딥리서치는 웹 검색과 자료 검증, 장문 리포트 작성이 핵심이다. 성격이 다른 과제를 하나의 프레임워크로 소화했다면 기술 범용성을 보여주는 사례가 될 수 있다는 계산이다.
달파가 말하는 경쟁력의 중심에는 ‘에이전트’가 있다. 단순 질의응답형 AI가 아니라, 스스로 정보를 찾고 판단하며 여러 단계의 작업을 이어 수행하는 형태다. 기업 고객 입장에서는 리서치, 운영 자동화, 수요 예측, 분석 보고서 작성까지 한 묶음으로 연결할 수 있다는 점에서 매력적인 그림이다. 최근 AI 업계가 “모델 성능”에서 “업무를 실제로 끝내는 에이전트” 경쟁으로 무게중심을 옮기고 있다는 점도 달파 같은 회사엔 기회 요인이다.
다만 벤치마크 1위가 곧바로 시장 우위로 이어진다고 보긴 어렵다. AI 업계에서 벤치마크는 기술 수준을 보여주는 유용한 참고 지표지만, 실제 기업 환경은 전혀 다른 변수를 요구한다. 고객 데이터 품질, 비용 구조, 보안 요구사항, 시스템 통합 난이도, 응답 안정성, 장애 대응, 현업 도입 편의성 같은 요소가 성패를 가른다. 벤치마크에서 높은 점수를 받은 시스템이 현장에서는 오히려 과도한 연산 비용이나 복잡한 운영 구조 때문에 힘을 못 쓰는 경우도 적지 않다.
이번 발표가 눈길을 끄는 또 다른 이유는 팀 규모다. 달파는 대규모 연구 조직이 아닌 소수정예 인력으로 글로벌 빅테크와 경쟁하고 있다는 점을 부각했다. 공동 창업진과 AI 연구진의 학업·경시대회 이력까지 공개한 것도 같은 맥락이다. 자본과 GPU 규모에서 열세인 국내 스타트업이 ‘인재 밀도’와 에이전트 설계 역량으로 승부하겠다는 메시지다. 한국 AI 스타트업 생태계에서도 자주 등장하는 서사이지만, 동시에 가장 냉정하게 검증받는 주장 가운데 하나이기도 하다.
김도균 달파 대표는 “거대 자본과 대규모 조직이 주도하는 글로벌 AI 경쟁에서 소수정예 팀이 서로 다른 세 영역의 벤치마크를 동시에 석권했다는 점이 가장 자랑스럽다”며 “달파는 인간의 행동을 이해하는 ‘소셜 월드모델(Social World Model)’이라는 차세대 파운데이션 모델을 개발하고 있다”고 말했다.
결국 시장이 궁금해하는 건 하나다. 벤치마크 성과가 실제 고객 가치로 이어질 수 있느냐다. 달파가 내세운 시계열 예측과 딥리서치 역량이 브랜드 수요 예측, 마케팅 자동화, 리서치 에이전트, 업무용 AI 비서 같은 상용 서비스에서 얼마나 설득력 있게 작동하는지가 다음 평가 기준이 될 가능성이 크다. AI 벤치마크 1위는 분명 강한 홍보 포인트다. 하지만 엔터프라이즈 AI 시장에서 더 오래 남는 회사는 대개 점수표보다 운영 성과로 기억된다.
Copyright ⓒ 스타트업엔 무단 전재 및 재배포 금지
본 콘텐츠는 뉴스픽 파트너스에서 공유된 콘텐츠입니다.



