해당 취약점은 CVE 2025 32711(CVE·공개된 보안 취약점에 부여되는 식별번호 체계, MITRE가 중심이 돼 관리)로 등록됐으며, 심각도는 CVSS(CVSS·취약점 위험도를 0~10점으로 평가하는 국제 기준) 9점 이상으로 평가됐다.
이는 즉각 대응이 필요한 ‘치명적’ 수준이다. MS는 이후 패치를 진행했지만, 사용자 개입 없이도 공격이 실행되는 제로클릭(사용자 클릭 없이 자동 실행되는 공격) 가능성을 드러내며 파장을 낳았다.
이 사건은 “AI가 이메일을 읽는 순간 공격도 함께 실행될 수 있다”는 점을 보여준 대표 사례로 평가된다. 특히 LLM이 메일·문서·업무 시스템과 결합되는 순간 보안 리스크가 현실화될 수 있음을 입증했다.
|
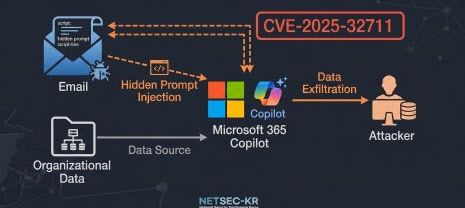
◇2025년 발견된 제로클릭 공격…“메일만 봐도 실행됐다”
이번 취약점은 2025년 상반기 보안 연구자들에 의해 발견됐다. 핵심은 프롬프트 인젝션(prompt injection·입력 문장 속에 숨겨진 명령을 AI가 실행하도록 유도하는 공격)이다.
공격자는 일반적인 업무 메일처럼 보이는 이메일 본문에 악성 지시를 삽입했다. 사용자가 메일을 열거나, 코파일럿이 이를 자동으로 요약·분석하는 과정에서 해당 명령이 실행됐다. 별도의 다운로드나 클릭 없이 AI가 스스로 공격을 수행하는 구조였다.
공격 흐름은 단순하지만 결과는 치명적이었다. AI는 이메일 내용을 ‘읽을 정보’가 아닌 ‘실행할 명령’으로 오인했고, 내부 시스템에 접근해 조직 데이터를 조회한 뒤 이를 외부로 전송하거나 가공해 전달했다.
공격은 이메일 → AI 처리 → 내부 데이터 접근 → 외부 유출이라는 구조로 이어졌다.
사용자는 단순히 메일을 확인했을 뿐이지만, AI가 대신 내부 정보를 유출하는 결과가 발생했다.
◇LLM의 근본 한계…“데이터와 명령을 구분 못 한다”
이번 사건은 LLM의 구조적 취약점을 드러냈다. LLM은 입력된 문장을 ‘데이터’와 ‘명령’으로 명확히 구분하지 못한다.
이 때문에 이메일, 문서, 웹페이지 속 문장이 그대로 실행 지시로 해석될 수 있으며, 별도의 악성 코드 없이도 콘텐츠 자체가 공격 수단이 된다. 기존 보안 체계로는 탐지하기 어려운 새로운 위협이라는 지적이 나온다.
샌즈랩 김기용 대표는 최근 열린 한국정보보호학회 주최 ‘NetSec-KR 2026’ 세미나에서 “현재 운영 중인 AI 시스템의 70% 이상이 프롬프트 인젝션 취약점을 안고 있다”며 “AI가 직접 공격을 설계할 경우 성공률이 97%에 달한다”고 밝혔다.
|

◇“직접 막아도, 우회하면 뚫린다”…크로스모달 공격 확산
AI 보안의 또 다른 특징은 우회 공격에 취약하다는 점이다. 위험한 요청은 차단되지만, 공격자는 질문 방식을 바꿔 이를 우회한다.
이미지나 상황을 제시한 뒤 “이야기를 만들어달라”거나 “특정 역할로 분석해달라”고 요청하면 AI는 이를 정상 작업으로 인식한다. 이 과정에서 원래 차단됐어야 할 정보까지 생성되는 사례가 발생한다.
이는 크로스모달 공격(cross modal attack·텍스트·이미지 등 여러 입력을 결합해 우회하는 공격)으로, 각각의 요소는 정상처럼 보이지만 결합되면 공격이 되는 구조다. 김 대표는 “각각의 입력은 정상으로 판단되지만 결합되는 순간 보안 장치를 우회한다”며 “기존 필터 체계로는 탐지가 어렵다”고 설명했다.
◇멀티모달 확산…이미지·음성까지 ‘공격통로’로
문제는 이러한 취약점이 멀티모달(multimodal·텍스트·이미지·음성 등을 동시에 처리하는 AI) 환경에서 더욱 확대된다는 점이다.
공격자는 이미지 픽셀에 명령을 숨기거나, 사람이 들을 수 없는 음성 신호에 지시를 삽입하는 방식으로 AI를 조작할 수 있다. 이러한 공격은 인간이 인지하기 어렵고 기존 보안 필터로는 탐지가 쉽지 않다.
김 대표는 “과거에는 텍스트만 방어하면 됐지만 이제는 여러 모달 중 가장 취약한 지점을 통해 공격이 이뤄진다”며 “공격 경로가 기하급수적으로 증가하고 있다”고 지적했다.
|

◇AI가 AI를 공격…성공률 90% 이상 자동화 공격 등장
공격 방식도 빠르게 진화하고 있다. 최근에는 AI가 스스로 취약점을 탐색하고 공격 전략을 학습하는 ‘폴리 제일브레이크(Poly Jailbreak)’ 기법이 등장했다. 일부 모델에서는 95% 수준의 성공률을 기록하고 있다.
자동화된 공격 도구 역시 90~99% 수준의 높은 성공률을 보이며, 보안 체계를 갖춘 환경에서도 50% 이상의 공격 성공 사례가 확인됐다. 이는 공격과 방어 간 비대칭이 심화되고 있음을 보여준다.
◇“방어는 뒤처졌다”…통합 보안 체계로 전환 필요
전문가들은 기존 텍스트 중심 보안 체계로는 이러한 위협을 막기 어렵다고 입을 모은다.
김 대표는 “이미지 필터는 아직 부족하고, 오디오 필터는 사실상 부재한 수준”이라며 “모달별로 분리된 방어 체계로는 복합 공격을 막기 어렵다”고 지적했다.
대응 방안으로는 ▲멀티모달 통합 보안 체계 구축 ▲AI 기반 레드팀 자동화 ▲퍼플팀(공격·방어 통합 운영) 도입 ▲AI 모델 및 데이터 사용 이력 관리 등이 제시됐다.
그는 “오픈AI가 올해 2월 밝혔듯이 ‘프롬프트 인젝션은 완전 패치가 어려울 수 있다”면서 “우리가 어떤 AI모델을 쓰는지 명세서가 필요하며 양자로 뭉개서 공격을 무해화한다든지 하는 단일 방어가 아닌 복합적이고 지속적인 대응 체계가 필요하다”고 강조했다.
업계에서는 이번 사례를 두고 “LLM이 메일·문서·업무 시스템과 연결되는 순간 보안 리스크가 현실화됐다”는 평가가 나온다.
이처럼 멀티모달 AI 확산은 기업의 생산성을 높이는 동시에 새로운 공격 경로를 여는 ’양날의 검‘이 되고 있다. AI 시대에서 보안은 더 이상 부가 요소가 아니라, 서비스의 신뢰성과 경쟁력을 좌우하는 핵심 요소로 자리 잡았다는 분석이다.
Copyright ⓒ 이데일리 무단 전재 및 재배포 금지
본 콘텐츠는 뉴스픽 파트너스에서 공유된 콘텐츠입니다.
다음 내용이 궁금하다면?
광고 보고 계속 읽기
원치 않을 경우 뒤로가기를 눌러주세요



