![[랭킹뉴스] 상위권 점수 140대 ‘밀집’…2026년 AI 모델 순위, 불과 몇 점 차](https://images-cdn.newspic.kr/detail_image/434/2026/4/25/8c7529f7-c866-4c02-a6cd-83bb603a4581.png)
글로벌 인공지능(AI) 모델 간 성능 경쟁이 한층 치열해졌다. 2026년 4월 기준 주요 AI 모델의 ‘IQ 테스트’ 성적에서 최상위권이 사실상 동일 수준으로 수렴하면서다.
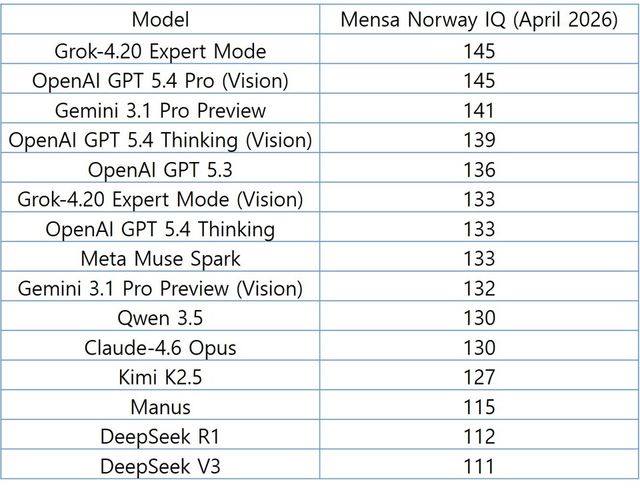
AI 분석 기관 TrackingAI가 공개한 ‘멘사 노르웨이 IQ 테스트’ 벤치마크에 따르면, xAI의 ‘Grok-4.20 Expert Mode’와 오픈AI의 ‘GPT 5.4 Pro(비전)’가 각각 145점을 기록하며 공동 1위에 올랐다. 뒤를 이어 구글의 ‘Gemini 3.1 Pro Preview’가 141점으로 추격하고 있다.
상위권 점수 분포를 보면 140점대 초반에 다수 모델이 몰려 있다. 4~5점 차이만으로 순위가 뒤바뀌는 구조다. AI 성능 경쟁이 ‘압도적 1위’에서 ‘미세한 격차 경쟁’으로 바뀌었다는 해석이 나온다.
◇ 2025년 최고 135점 → 2026년 145점…시각 문제 해결 능력 강화
이번 결과에서 눈에 띄는 부분은 점수 상승 폭이다. 2025년 동일 테스트 최고 점수는 135점 수준이었으나, 1년 만에 145점까지 올라섰다.
특히 이미지 기반 문제 해결 능력, 즉 ‘비전 모델’ 성능이 순위에 큰 영향을 미쳤다. GPT 5.4 Pro(비전), Grok 비전 모델 등 시각 정보를 직접 처리하는 모델이 상위권에 다수 포진했다.
반면 텍스트 기반 모델은 문제를 언어로 변환해 풀어야 하기 때문에 상대적으로 불리한 구조다. 같은 모델이라도 ‘비전 여부’에 따라 점수 차가 발생한 이유다.
◇ GPT·Gemini·Claude·Qwen ‘상위권 밀집’
상위 10위권을 보면 주요 빅테크 AI 모델이 대부분 포함됐다. 오픈AI 계열 모델(GPT 5.4 Thinking, GPT 5.3), 구글 Gemini, 메타의 Muse Spark, 알리바바 계열 Qwen, 앤트로픽 Claude 등 주요 플레이어가 모두 경쟁 중이다.
다만 점수 차는 크지 않다. 1위(145점)와 10위권(130점 내외) 간 격차는 약 15점 수준이며, 상위 5개 모델 간 격차는 사실상 한 자릿수에 그친다.
AI 업계 관계자들 사이에서는 “성능 경쟁이 임계 구간에 진입했다”는 평가도 나온다. 단일 기술 혁신보다 미세한 최적화 경쟁이 중요해졌다는 의미다.
◇ 하위권과 격차 확대…모델 간 양극화도 뚜렷
모든 AI 모델이 같은 속도로 발전하는 것은 아니다. DeepSeek 계열 모델은 110점대 초반, 일부 모델은 100점 이하 점수를 기록하며 상위권과 격차를 보였다. 특히 Mistral의 주요 모델은 97점으로 집계돼 상위 그룹과 큰 차이를 나타냈다. AI 시장 내 ‘초격차 모델’과 ‘추격 그룹’ 간 간극이 동시에 벌어지는 양상이다.
◇ 시각 패턴 문제 중심…코딩·추론·신뢰성 평가는 제외
이번 벤치마크는 대중에게 익숙한 IQ 테스트를 활용했다는 점에서 직관적인 비교가 가능하다. 다만 해석에는 주의가 필요하다.
멘사 노르웨이 테스트는 35개 시각 패턴 문제로 구성돼 있다. 따라서 실제 AI 성능 중 일부 영역만 반영한다.
코딩 능력, 사실 정확도, 장기 추론, 도구 활용 능력 등은 평가 대상에 포함되지 않는다. 또한 모델이 답변을 거부할 경우 최대 10번까지 재질문 후 마지막 답변을 반영하는 방식도 변수로 작용할 수 있다. 결국 이 지표는 ‘전반적 지능’이 아니라 ‘시각적 추론 능력’에 가까운 참고 지표로 보는 것이 적절하다.
AI 모델 경쟁은 새로운 국면에 들어섰다. 과거처럼 한 기업이 크게 앞서는 구조가 아니라, 주요 플레이어가 거의 같은 수준에서 경쟁하는 구도다. 앞으로 성능 격차는 단순 점수보다 실제 활용성, 산업 적용 능력, 비용 효율성에서 갈릴 가능성이 크다.
AI 경쟁의 무게 중심이 ‘누가 더 똑똑한가’에서 ‘누가 더 잘 쓰이는가’로 이동하는 흐름도 감지된다.
Copyright ⓒ 스타트업엔 무단 전재 및 재배포 금지
본 콘텐츠는 뉴스픽 파트너스에서 공유된 콘텐츠입니다.



