ㅣ데일리포스트=곽민구 기자ㅣ알리바바 그룹이 복합적인 업무와 소프트웨어 개발을 자율적으로 수행하는 ‘Qwen3.6-Plus’와 통합 멀티모달 처리 능력을 갖춘 ‘Qwen3.5-Omni’를 출시했다.
이번에 공개된 두 모델은 각각 ‘에이전틱(Agentic) 실행’과 ‘옴니모달 인텔리전스’ 강화에 초점을 맞췄다. ‘Qwen3.6-Plus’는 자율 코딩과 추론에, ‘Qwen3.5-Omni’는 텍스트·음성·이미지·영상의 통합 이해 및 생성에 특화된 것이 특징이다.
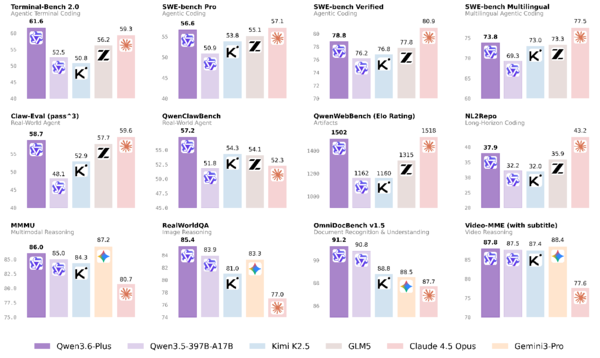
플래그십 모델인 ‘Qwen3.6-Plus’는 단순한 질의응답 차원을 넘어 저장소(Repository) 단위의 엔지니어링 작업과 실제 시각 환경 기반의 문제 해결을 수행한다. 특히 인식·추론·행동을 하나의 워크플로로 연결하는 ‘능력 루프(Capability Loop)’ 구조를 통해 코드 구상부터 테스트, 개선까지 전 과정을 자율적으로 처리한다.
또 100만 토큰의 컨텍스트 창을 지원하며, UI 스크린샷이나 손그림 와이어프레임을 해석해 실제 동작하는 프론트엔드 코드를 생성하는 시각적 코딩 기능도 갖췄다. 해당 모델은 알리바바의 ‘모델 스튜디오(Model Studio)’와 ‘큐웬 챗(Qwen Chat)’에서 이용할 수 있으며, 클로드 코드(Claude Code) 등 외부 도구와도 호환된다.
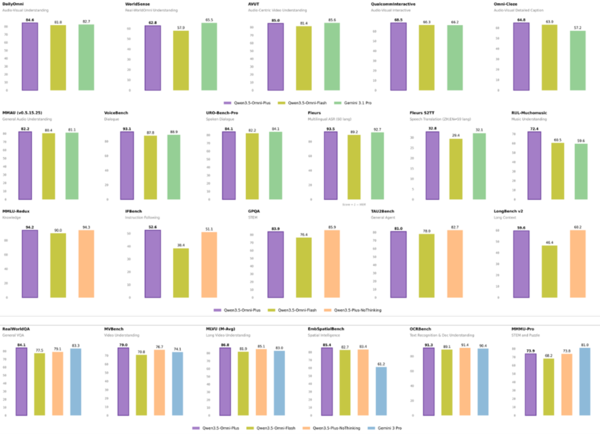
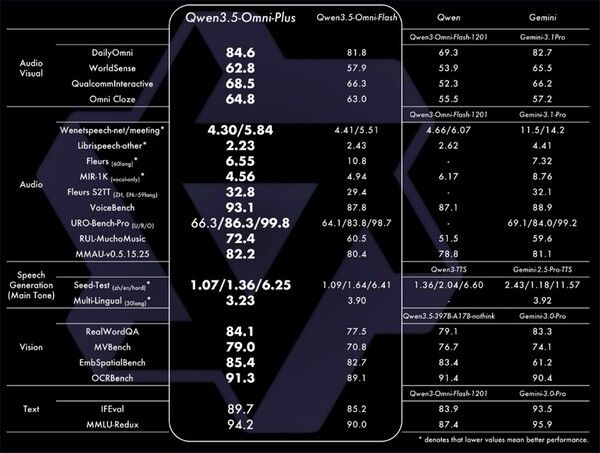
함께 공개된 ‘Qwen3.5-Omni’는 단일 모델 내에서 텍스트와 음성, 영상 등을 통합 처리하는 옴니모달 모델로, 113개 언어의 음성 인식과 36개 언어의 음성 생성을 지원한다. 10시간 이상의 연속 오디오를 처리할 수 있는 성능을 보유했다.
특히 ‘오디오-비주얼 바이브 코딩(Audio-Visual Vibe Coding)’ 기능을 통해 사용자가 스케치를 보여주며 음성으로 설명하면 앱이나 웹사이트용 UI를 즉석에서 생성한다. 실시간 상호작용 시 음량과 속도, 감정 표현까지 세밀하게 제어할 수 있어 지능형 음성 비서나 라이브 스트리밍 분야에서 활용도가 높을 것으로 보인다.
알리바바 관계자는 “기업 환경에 최적화된 안정성과 정확도를 바탕으로 실제 업무 자동화 역량을 끌어올리는 데 주력했다”며 “향후 일부 모델을 오픈소스 형태로 공개해 개발자 생태계 지원도 지속하겠다”고 밝혔다.
Copyright ⓒ 데일리 포스트 무단 전재 및 재배포 금지
본 콘텐츠는 뉴스픽 파트너스에서 공유된 콘텐츠입니다.



