1. On-premise RAG AI 환경에서 다시 보는 CPU의 역할
생성형 AI 성능을 이야기할 때 시장의 관심은 대개 GPU로 향한다. 실제로 대형언어모델(LLM)의 추론과 응답 생성에서 GPU는 가장 무거운 연산을 담당하는 핵심 장치다. 그렇다고 기준을 모든 AI 시스템에 그대로 대입하는 것은 정확하지 않다. 특히 개인 PC나 소규모 조직이 자체 구축해 운용하는 on-premise RAG AI 환경에서는 성능을 좌우하는 요인이 조금 다르게 나타난다.
RAG(Retrieval-Augmented Generation)는 질문이 들어오면 곧바로 답을 생성하는 대신, 먼저 관련 문서를 검색하고 나온 결과를 문맥으로 결합한 뒤 LLM이 응답을 생성한다. 문제는 이 과정에서 문서 탐색, 벡터 검색, 프롬프트 조립 같은 선행 단계 대부분을 CPU가 맡는다. 다시 말해 GPU가 답변의 '생성 엔진'이라면, CPU는 생성이 시작되기 전 필요한 정보를 얼마나 빠르게 준비해 줄 수 있는지를 좌우하는 역할을 담당한다. 실제로 RAG 파이프라인에서 벡터 검색은 전체 지연 시간에서 꽤나 의미 있는 비중을 차지하며, 질의가 들어올 때마다 반복 실행되기 때문에 CPU 성능 차이가 전체 체감 응답성으로 이어질 수 있다.

그 점에서 주목해야 할 것 바로 AMD X3D 계열 프로세서다.
게임용 CPU라는 이미지가 강했던 제품군이, 정작 AI 워크로드 중에서도 RAG처럼 검색 비중이 높은 환경에서는 의외로 더 설득력 있는 장점을 보여주기 때문이다. 결론부터 말하면, 개인 PC 및 소규모 on-premise RAG AI 환경에서는 GPU만으로 성능이 결정되지 않는다. GPU가 생성 자체를 담당하더라도, CPU의 벡터 검색 성능과 L3 캐시 크기는 검색 처리량, 인덱스 구축 시간, 동시 처리량에 의미 있는 차이를 만든다.
2. RAG에서는 왜 CPU가 다시 중요한가?
일반적인 생성형 AI 사용자는 답변이 화면에 표시되는 마지막 순간만 체감한다. 하지만 그 이전에는 적지 않은 준비 과정이 존재한다. 사용자가 질문을 입력하면 시스템은 먼저 질의를 처리 가능한 형태로 변환하고, 이를 바탕으로 벡터 데이터베이스에서 관련 문서를 검색한 뒤, 검색 결과와 사용자 질문을 하나의 프롬프트로 조립해 GPU에 넘긴다.
이후 GPU가 본격적인 추론을 수행해 답변을 생성하고, 마지막 후처리 과정 일부가 다시 CPU에서 이뤄진다. 가장 중요한 CPU의 역할이라면 단연 벡터 검색이다. 전체 파이프라인에서 GPU 추론 비중이 가장 크더라도, 벡터 검색은 별도의 독립 단계로 반복 실행되며 지연이 누적되기 쉽다. 특히 사내 문서 검색이나 개인 지식베이스처럼 RAG 활용이 잦은 환경에서는, 미묘한 성능 차이가 시스템 전체의 반응에 영향을 준다.
사실 벡터 검색이 CPU 의존적이라는 점은 알고리즘 구조와도 관련이 깊다.
대표적인 벡터 검색 방식인 HNSW는 데이터가 그래프 형태로 연결된 상태에서 가장 유사한 문서를 찾기 위해 이 노드 저 노드를 빠르게 오가며 탐색한다. 문제는 작업이 연속적인 메모리 읽기보다 불규칙한 랜덤 메모리 접근에 가깝다는 점이다. 즉, 정렬된 구간을 쭉 읽는 것이 아니라 메모리의 여러 지점을 불규칙하게 참조하는 랜덤 메모리 액세스 성격이 강하다. 순차 처리 중심의 워크로드와 달리, 연산에서는 단순한 클럭 수치만으로 성능을 설명하기 어렵다. 필요한 데이터가 CPU 내부의 고속 캐시에 머물러 있느냐, 아니면 더 느린 메인 메모리까지 내려가느냐가 체감 성능을 크게 갈라놓기 때문이다.
그렇기에 X3D의 구조적 특징이 의미를 지닌다.

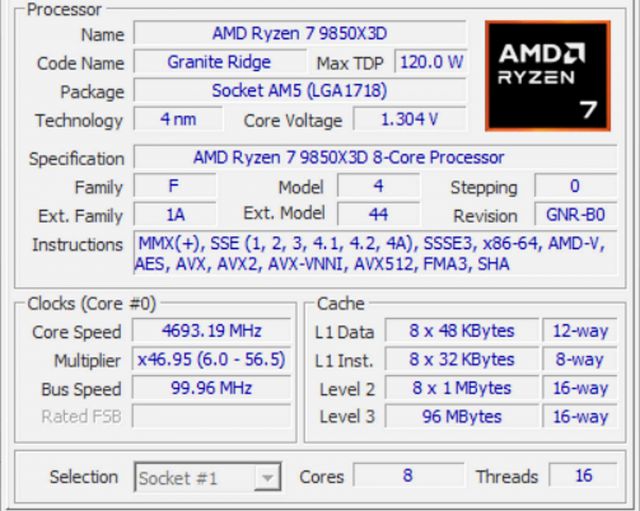
▲ R7 9850X3D 시피유는 L3 캐시가 무려 96MB에 달한다.
X3D는 3D V-Cache를 통해 일반 모델보다 훨씬 큰 L3 캐시를 갖추고 있다. RAG 벡터 검색에서는 탐색 중 자주 참조되는 그래프 노드와 관련 데이터가 더 많이 캐시에 담아낼 수록 메인 메모리인 DRAM 에 접근하는 빈도가 줄어든다. 캐시 적중률이 높아지면 검색 지연은 줄고, 같은 시간 안에 더 많은 질의를 처리할 수 있게 된다.
X3D가 게임에서 높은 평가를 받아온 이유도 본질적으로는 비슷하다. 씬 그래프와 오브젝트 데이터를 빠르게 참조해야 하는 게임 엔진, 그리고 노드를 따라가며 유사 문서를 찾는 RAG 벡터 검색은 서로 다른 분야이지만 메모리 접근 특성만 놓고 보면 유사한 메커니즘이다.
그렇다고 해서 X3D가 모든 AI에 유리하다는 식으로 일반화해서는 안 된다. 모든 AI 연산이 이와 같은 메모리 접근 특성을 보이는 것은 아니며, 특히 GPU 중심의 대규모 모델 추론만 놓고 보면 CPU 캐시 효과는 상대적으로 덜 드러날 수 있다. 반대로, 검색이 반복되고 문서 인덱싱이 자주 이뤄지는 on-premise RAG AI 환경에서는 X3D의 대용량 L3 캐시가 현실적인 장점으로 이어질 가능성이 높다.
3. x3d-rag-benchmark의 방법론을 바탕으로 벤치마크
실증 데이터 확보를 위해 측정은 공개 벤치마크인 x3d-rag-benchmark의 방법론을 바탕으로 이뤄졌다. 벡터 검색 엔진은 Meta FAISS의 HNSW 알고리즘을 사용했고, 임베딩 모델은 all-MiniLM-L6-v2, 데이터셋은 Simple English Wikipedia 문서 임베딩을 활용했다. 측정 항목은 크게 3가지다.
첫째는 배치 벡터 검색 QPS, 둘째는 HNSW 인덱스 구축 시간, 셋째는 동시 요청이 걸린 RAG 파이프라인의 처리량과 TTFT를 비교했다. 다시 말해 단순 검색 속도를 시작으로 제로 문서를 색인하고 여러 요청을 동시에 감당할 때의 성능까지 함께 체크한 셈이다. 절대적인 CPU 서열을 매기기 위한 범용 테스트라기보다, RAG 검색 워크로드에서 어떤 하드웨어 속성이 실질적인 차이를 만드는지를 보기 위한 성격이 강하다.
◆ 테스트 환경
| Item | Details |
|---|---|
| Vector Search Engine | Meta FAISS (HNSW algorithm) |
| Embedding Model | all-MiniLM-L6-v2 (sentence-transformers) |
| Dataset | Wikipedia (Simple English) — real document embeddings |
| DB Size | 100K / 200K vectors (384 dim) |
| GPU | NVIDIA GeForce RTX 5080 (16GB) |
| RAM | DDR5 ~31GB (identical config) |
| OS | Ubuntu 24.04 LTS (Linux native) |
| LLM (for TTFT) | llama3.2 via Ollama |
| Runs | 10 runs, trimmed mean (top/bottom 5% dropped) |
| Variance Controls | CPU governor → performance | NUMA balancing off | THP → disabled | Process nice → -20 |
| Measurement Stability | Python GC disabled | Inter-run 2s cooling | Warmup 30 queries discarded per run |
테스트 환경은 비교의 공정성을 높이기 위해 엄격하게 통제됐다.
기본 원칙은 동일한 환경에서 CPU만 교체하는 방식이다.
벡터 검색 엔진은 Meta FAISS(HNSW), 임베딩 모델은 sentence-transformers 계열의 all-MiniLM-L6-v2, 데이터셋은 실제 문서 임베딩 기반의 Simple English Wikipedia를 사용했고, 데이터베이스 크기는 100K와 200K 벡터(384차원)로 맞췄다. GPU는 NVIDIA GeForce RTX 5080 16GB, 메모리는 DDR5 약 31GB, 운영체제는 Ubuntu 24.04 LTS로 통일했고, TTFT 측정에는 llama3.2 via Ollama가 활용됐다.
또한 각 항목은 10회 반복 후 상하위 5%를 제외한 trimmed mean으로 계산했으며, CPU governor를 performance로 고정하고 NUMA balancing과 THP를 비활성화했으며, 프로세스 nice 값을 -20으로 조정하는 식으로 변수를 최소화했다. Python GC를 끄고 런 사이에 2초 냉각 시간을 두었으며, 워밍업 성격의 30개 쿼리는 매 실행마다 제외해 측정 안정성을 높였다. 즉, 결과를 특정 CPU 외의 요인으로 설명하기 어렵게 만들기 위함이다.
결과를 보면, X3D의 강점은 비교적 분명하게 드러난다.
| 항목 | 9850X3D | 9700X | Ultra 9 285K | Ultra 7 270K+ | Ultra 7 265K |
|---|---|---|---|---|---|
| Batch Vector Search QPS (높을수록 좋음) | 81,193 | 34,692 | 47,388 | 48,045 | 45,713 |
| HNSW Index Build Time, sec (낮을수록 좋음) | 2.49s | 5.92s | 4.30s | 4.16s | 4.75s |
비교 대상은 Ryzen 7 9850X3D, Ryzen 7 9700X, Intel Core Ultra 9 285K, Ultra 7 270K+, Ultra 7 265K다. 먼저 100K vectors 구간에서 9850X3D는 배치 벡터 검색 성능 81,193 QPS를 기록해 가장 높은 수치를 보였다. 뒤이어 270K+가 48,045 QPS, 285K가 47,388 QPS, 265K가 45,713 QPS, 9700X가 34,692 QPS로 집계됐다. 같은 데이터셋에서 HNSW 인덱스 구축 시간 역시 9850X3D가 2.49초로 가장 빨랐고, 270K+ 4.16초, 285K 4.30초, 265K 4.75초, 9700X 5.92초 순이다. 이는 9850X3D가 단순히 검색 처리량만 높은 것이 아니라, 실제 RAG 시스템 구축 과정에서 필요한 인덱스 생성 단계까지도 빠르게 수행한다는 뜻이다.
| 항목 | 9850X3D | 9700X | Ultra 9 285K | Ultra 7 270K+ | Ultra 7 265K |
|---|---|---|---|---|---|
| Batch Vector Search QPS (높을수록 좋음) | 51,050 | 33,379 | 46,036 | 45,310 | 43,685 |
| HNSW Index Build Time, sec (낮을수록 좋음) | 8.56s | 15.10s | 11.12s | 10.82s | 11.88s |
데이터 규모를 200K vectors로 늘리면 CPU 간 차이는 줄어들지만, 순위는 명확해진다. 9850X3D는 51,050 QPS를 기록해 1위를 지켰고, 285K가 46,036 QPS, 270K+가 45,310 QPS, 265K가 43,685 QPS, 9700X가 33,379 QPS로 뒤를 따랐다. 인덱스 구축 시간 역시 9850X3D가 8.56초로 가장 짧았고, 270K+ 10.82초, 285K 11.12초, 265K 11.88초, 9700X 15.10초 순이다.
소규모 RAG 환경에서는 데이터셋이 수시로 갱신되거나 문서 추가에 따라 인덱스를 다시 생성해야 하는 경우가 많다. 이때 인덱스 빌드 시간이 짧다는 것은 서비스 운영의 유연성을 높여 준다. 검색 성능뿐 아니라 준비 시간까지 짧다면, 실제 현장에서 느끼는 생산성 차이는 더 크게 벌어질 수 있다.
| 항목 | 9850X3D | 9700X | Ultra 9 285K | Ultra 7 270K+ | Ultra 7 265K |
|---|---|---|---|---|---|
| Throughput, req/s (높을수록 좋음) | 24.24 | 18.02 | 19.48 | 20.88 | 20.14 |
| Avg TTFT, ms (낮을수록 좋음) | 119.4ms | 119.0ms | 150.3ms | 130.4ms | 128.0ms |
실사용에 더 가까운 지표는 따로 있다. 바로 Concurrent RAG pipeline 결과다. 총 8개 동시 워커가 벡터 검색과 LLM 응답을 병렬로 수행하는, 보다 실사용에 가까운 형태의 시나리오에서. 9850X3D는 24.24 req/s로 가장 높은 처리량을 기록했다. 270K+는 20.88 req/s, 265K는 20.14 req/s, 285K는 19.48 req/s, 9700X는 18.02 req/s다. 동시 요청이 걸리는 상황일수록 CPU가 검색과 데이터 준비를 얼마나 빠르게 처리하느냐가 전체 처리량을 좌우한다는 점을 보여주는 대목이다. 단일 질의 응답만 놓고 보면 차이가 작아 보일 수 있지만, 실제 업무 환경에서 여러 사용자가 동시에 질의하는 상황을 가정하면 격차는 의미가 있다.
반면 평균 TTFT에서는 조금 더 세심한 해석이 필요하다. 9700X는 119.0ms, 9850X3D는 119.4ms로 사실상 같은 수준을 보였다. 뒤이어 265K 128.0ms, 270K+ 130.4ms, 285K 150.3ms가 기록됐다. 이것만 보면 X3D의 장점이 모든 체감 지표에서 무조건 압도적이라는 식으로 단순화될 수 없음을 뜻한다. 첫 토큰이 출력되기 시작하는 순간의 반응성은 GPU 추론과 CPU 전처리, 파이프라인 구성 방식이 함께 영향을 주기 때문에 특정 한 요소만으로 설명하기 어렵다. 그러나 동시에, 검색 처리량과 인덱스 구축 속도, 다중 요청 처리량처럼 RAG의 CPU 의존 구간에서는 9850X3D의 우위가 훨씬 선명하게 드러난다.
AI는 GPU가 전부라는 기존 통념은 틀렸다.
본질적인 메시지는, AI 성능을 GPU 하나로 설명하는 방식이 on-premise RAG 환경에서는 충분하지 않다는 데 있다. 물론 초거대 모델 추론 자체는 여전히 GPU가 좌우한다. 하지만 로컬 AI, 사내 문서 검색, 소규모 팀의 지식베이스 자동화처럼 RAG 활용이 실질적인 생산성 도구로 쓰이는 환경에서는 이야기가 달라진다. 사용자는 답변의 품질뿐 아니라 검색 속도, 문서 추가 후 반영 시간, 동시 요청에서의 안정성까지 함께 체감한다.

이 경우 CPU는 시스템 효율을 좌우하는 핵심 부품이 된다. GPU가 아무리 빠르더라도 CPU가 검색 단계에서 병목을 만들면 시스템은 기대한 만큼 민첩하지 않다. 반대로 같은 GPU를 쓰더라도 CPU의 벡터 검색 성능과 캐시 구조가 유리하면 전체 응답 체감은 달라진다. 로컬 AI PC와 소규모 온프레미스 RAG 시스템이 보급될수록, 차이가 중요한 구매 기준이 될 가능성이 높다.
물론 해석에는 분명한 선이 필요하다. 결과는 대규모 데이터센터 AI 전체를 설명하는 지표가 아니다. 분산형 검색 시스템, 별도 추론 노드와 검색 노드가 분리된 수백만~수천만 벡터 규모의 서비스 환경에서는 또 다른 병목이 등장한다. 또한, 명확히 RAG 검색 중심 워크로드에 초점을 뒀다. 따라서 이미지 생성, 대규모 학습, 완전한 GPU 주도형 추론 서버 같은 다른 영역에 같은 결론을 기계적으로 적용해서는 안 된다.
그럼에도 불구하고 의미가 작지 않다. 적어도 개인 PC와 소규모 온프레미스 RAG 환경에서는 CPU의 L3 캐시와 벡터 검색 성능이 실제 지표 차이로 드러났고, 그 결과 X3D는 게임에 강한 CPU도 되지만, 검색 중심 AI에도 유리한 CPU라는 새로운 해석 가능성을 보여줬다.
** 편집자 주 = RAG 시대, X3D는 게임 밖에서도 설득력을 갖는다
한동안 X3D는 게이머의 CPU로 기억돼 왔다. 하지만 로컬 LLM과 사내 문서 기반 AI 활용이 늘어나는 지금, 대용량 캐시는 전혀 다른 용도에서 새로운 의미가 더해진 상황. 문서를 빠르게 찾고, 검색 결과를 프롬프트로 엮고, 동시에 여러 요청을 감당해야 하는 on-premise RAG AI 환경에서는 대용량 캐시가 성능을 좌우하는 중요한 변수로 떠오르는 것. 이는 GPU가 생성 자체를 담당하더라도, CPU의 벡터 검색 성능과 L3 캐시 크기가 검색 처리량, 인덱스 구축 시간, 동시 처리량에 실질적인 차이를 만든다는 것에 실증 데이터를 통해 분명하게 입증된 사례다.

질문은 이제 달라져야 한다. AI에 어떤 GPU가 필요한가? 도 필요하지만, RAG 워크로드를 가장 효율적으로 대응하는 CPU가 무엇인가? 다. 그리고 실증 결과를 보면 적어도 개인 PC 및 소규모 on-premise RAG AI 환경에서는, X3D가 생각보다 훨씬 잘 맞는다.. AI PC 시대를 말할 때 GPU가 가장 화려한 주역인 것은 분명하지만, 적어도 RAG라는 무대에서는 CPU, 그리고 그 안의 캐시 설계가 성능의 방향을 바꾸는 중요한 변수임이 명확하다.
본 콘텐츠는 뉴스픽 파트너스에서 공유된 콘텐츠입니다.
다음 내용이 궁금하다면?
광고 보고 계속 읽기
원치 않을 경우 뒤로가기를 눌러주세요