AI CCTV를 가능하게 핵심 기술은 이미지와 텍스트를 연결해 학습하는 멀티모달 AI이다. 가장 널리 쓰이는 멀티모달 모델은 오픈AI의 ‘CLIP(Contrastive Language Image Pre-training)’이다. 초창기 모델로 영상 인공 지능 분야에서 널리 활용되고 있지만, CLIP은 입력 텍스트를 77개 토큰으로 제한해 긴 문장을 인식하지 못하는 한계가 있다.
최근 국내 연구진이 이를 극복한 기술을 개발, 세계적인 인공지능 학회인 CVPR 2025에 발표해 주목을 받았다. 엄찬호 중앙대 첨단영상대학원 교수 연구팀(최현규 학부생과 장영균 구글 딥마인드 박사가 공동 참여)이 개발한 ‘GOAL(Global-local Object Alignment Learning)’은 기존 CLIP 대비 데이터를 100분의 1만 쓰고 학습 시간도 짧지만, 훨씬 더 긴 이미지 문장을 인식하며 이미지를 효율적으로 검색한다.
엄찬호 교수는 “이미지를 잘게 쪼개고 CLIP이 기존에 원래 알고 있던 사전 지식을 활용해서 두 매칭 관계를 풀었다”면서 “목격자가 범죄자의 인상착의를 ‘남성이고 체크색 셔츠를 입었고 턱수염이 있다’는 식으로 길게 진술해도 CCTV에서 찾을 수 있는 관제시스템을 목표로 연구를 시작했다”고 말했다.
관제 인력은 감소 CCTV는 급증…AI 역할 필수
|

|
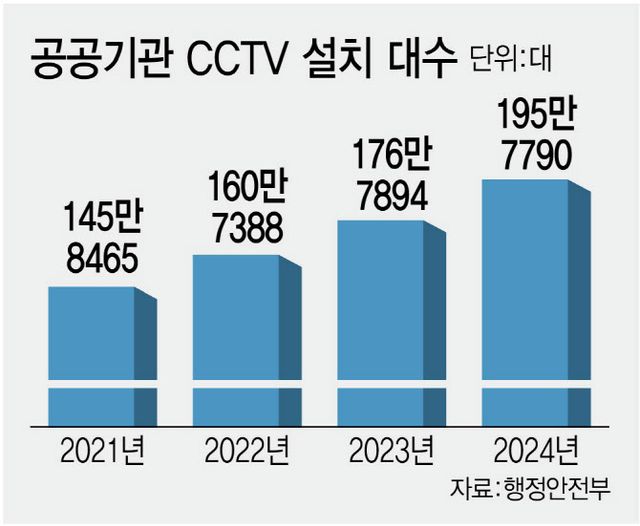
관제 장비는 늘고 인력은 줄면서, AI CCTV의 역할은 더 커질 전망이다. 행정안전부에 따르면 2024년 기준 전국 공공기관에 설치된 CCTV는 약 195만 대로 매년 약 10%씩 증가해왔다. 반면 이를 직접 감시·운영하는 관제 인력은 2011년 9200여명에서 2024년 4093명으로 절반 이하로 줄었다.
범죄 수사 뿐 아니라 실종, 군집 분석 마케팅 등 AI CCTV의 활용 사례는 무궁무진하다. 최근에는 경기도 안양에서 AI CCTV가 1초만에 88세 실종 노인을 찾은 사례도 있었다.
민간에서도 AI CCTV 연구 개발이 활발하다. 물리보안 전문기업 에스원은 최근 자사 지능형 CCTV 시스템에 ‘AI 에이전트’를 탑재했다. AI 에이전트는 위급 상황 발생 시 표준운영절차(SOP)를 실시간으로 안내하고, 대화형 영상 검색 및 CCTV 제어 서비스를 제공한다. AI CCTV가 “지하실 입구 카메라 5분 전 영상 보여줘“라는 음성을 인식하고, “창고에서 남성이 쓰러졌습니다”라는 알리며 119 연락 등 행동 지침을 알려준다.
에스원은 실시간 영상 분석과 동시에 상황별 대응 시나리오를 생성하기 위해 실제 현장 데이터를 학습시켰고, 음성 명령만으로 CCTV를 제어하는 대화형 인터페이스는 자연어 이해 기술과 영상 검색 알고리즘의 통합 최적화를 통해 구현했다.
에스원 R&D센터 영상솔루션팀 이동성 부사장은 “AI 에이전트 개발을 위해 이상상황 감지 등 보안과 안전 분야에 특화된 영상언어모델(VLM)을 내재화했고, 이를 기반으로 자연어 처리 기술을 결합한 멀티모달 AI Agentic 아키텍처를 구축했다”고 말했다.
Copyright ⓒ 이데일리 무단 전재 및 재배포 금지
본 콘텐츠는 뉴스픽 파트너스에서 공유된 콘텐츠입니다.
다음 내용이 궁금하다면?
광고 보고 계속 읽기
원치 않을 경우 뒤로가기를 눌러주세요



