中 AI 기업 딥시크, 신규 모델 공개… 화웨이·하이곤 등 자국산 AI 칩 생태계 지원
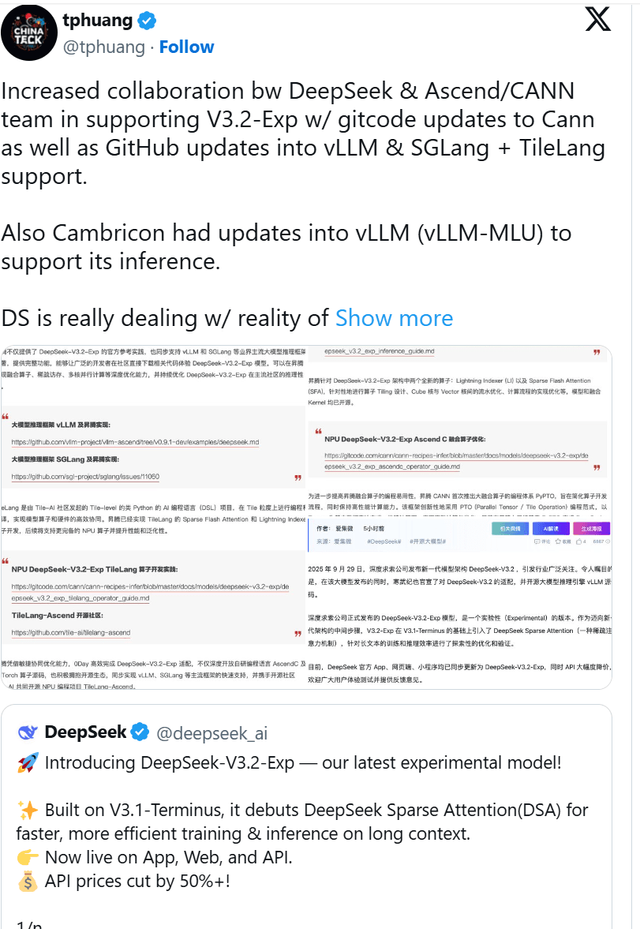
중국의 AI 스타트업 딥시크(DeepSeek)가 최신 거대 언어 모델(LLM)인 'DeepSeek-V3.2-Exp'를 출시했습니다. 이번 출시는 엔비디아의 CUDA 생태계에서 벗어나 화웨이의 어센드(Ascend) 하드웨어와 CANN 소프트웨어 스택을 우선적으로 지원한다는 점에서 중국 AI 산업의 중요한 변화를 시사합니다.
엔비디아 CUDA 대안으로 떠오르는 화웨이 CANN
딥시크는 지난 9월 29일, 기술 보고서와 함께 모델의 코드와 체크포.인.트를 허깅페이스(Hugging Face)에 공개했습니다. 회사 측은 이번 모델을 "차세대 아키텍처를 향한 중간 단계"라고 설명하며, 긴 컨텍스트(long-context) 추론 비용을 절감하도록 설계되었다고 밝혔습니다. 특히 출력 품질을 유지하면서 메모리와 연산 요구량을 조절하는 '희소 어텐션(sparse attention)' 메커니즘이 특징입니다.
이번 모델 공개에 맞춰 화웨이 어센드 팀과 관련 커뮤니티는 발 빠르게 움직였습니다. vLLM-Ascend 저장소에는 DeepSeek-V3.2-Exp 모델을 어센드 NPU에서 지원하기 위한 맞춤형 커널 패키징 및 설치 단계가 즉시 추가되었습니다. 화웨이의 CANN(Compute Architecture for Neural Networks) 팀 또한 추론 레시피를 공개하며, 화웨이 하드웨어에서 곧바로 모델을 배포할 수 있도록 지원에 나섰습니다.
이러한 움직임에는 다른 중국 칩 제조사들도 동참했습니다. **캠브리콘(Cambricon)**은 자사의 vLLM-MLU 포크 업데이트를 발표하며 모델의 희소 어텐션 기술과 결합하면 긴 시퀀스 처리 비용이 절감된다고 밝혔습니다. 하이곤(Hygon) 역시 자사의 DCU 가속기가 DTK 소프트웨어 스택을 통해 '제로 대기(zero-wait)' 배포가 가능하도록 조정되었다고 발표했습니다.
탈(脫)엔비디아 가속화하는 중국 AI 생태계
딥시크의 이번 발표는 중국 AI 생태계가 미국의 제재 등으로 엔비디아 하드웨어에 대한 접근이 불확실한 미래에 어떻게 대비하고 있는지를 명확히 보여줍니다.
딥시크는 발표에서 엔비디아의 CUDA 커널을 직접 언급하면서도, 동일한 모델을 최소한의 변경만으로 엔비디아와 중국산 가속기 모두에 배포할 수 있다는 점을 강조했습니다. 이는 중국 기업들이 단순히 사후 호환성을 확보하는 수준을 넘어, 처음부터 자국 플랫폼을 최우선 목표로 삼고 있음을 보여줍니다.
AI 학습과 추론에서 엔비디아의 CUDA가 여전히 독보적인 위치를 차지하고 있지만, 딥시크의 이번 출시는 중국 주요 기업이 비(非) CUDA 스택에 최적화된 결과물을 내놓은 첫 사례 중 하나입니다. 화웨이, 캠브리콘, 하이곤의 이러한 협력은 'AI 주권'을 확보하려는 중국의 의지가 얼마나 확고한지를 보여주는 가장 분명한 신호입니다.
Copyright ⓒ 시보드 무단 전재 및 재배포 금지
본 콘텐츠는 뉴스픽 파트너스에서 공유된 콘텐츠입니다.



