[한스경제=박정현 기자] KT의 거대언어모델(LLM) '믿:음 2.0 베이스'가 한국어 인공지능(AI) 성능 평가 플랫폼 '호랑이(Horangi) 리더보드'에서 종합 성능 1위를 차지했다.
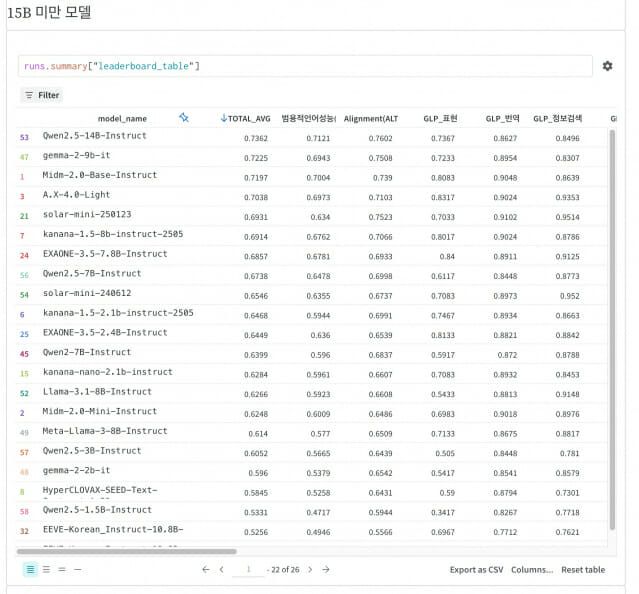
9일 KT는 믿:음 2.0 베이스가 종합 점수 0.7197로 파라미터 수 150억개 미만 국내 모델 중 1위를 차지했다고 밝혔다. 전 세계 동급 모델 중에서는 3위다.
호랑이 리더보드는 글로벌 머신러닝 운영(MLOps) 업체 웨이트앤바이어스(W&B)가 주관하는 한국어 특화 LLM 평가 지표다.
KT 관계자는 "호랑이 리더보드는 한국어 고유의 문맥, 표현, 사회적 맥락 등을 반영하는지 평가한다는 점에서 AI 모델이 국내 시장에서의 실효성을 가지는지 가늠하는 지표"라며 "믿:음 2.0이 국산 기술력 기반의 한국어 AI 모델로서 실질적 경쟁력을 갖추었음을 객관적으로 입증했다"고 강조했다.
KT는 믿:음 2.0 기반 기업대기업(B2B) 솔루션을 산업 전반에 공급하며 공공·금융·교육·법률 분야에서 실증을 추진할 계획이다.
신동훈 KT 최고AI책임자((CAIO·상무)는 "믿:음 2.0을 국내 다양한 산업 분야에 적용해 '한국적 AI' 시장 확산에 본격적으로 나설 것"이라고 말했다.
Copyright ⓒ 한스경제 무단 전재 및 재배포 금지
본 콘텐츠는 뉴스픽 파트너스에서 공유된 콘텐츠입니다.
다음 내용이 궁금하다면?
광고 보고 계속 읽기
원치 않을 경우 뒤로가기를 눌러주세요



