
[센머니=현요셉 기자] ElevenLabs가 텍스트 음성 변환(TTS) 분야에서 혁신적인 발전을 선보이며, 'Eleven v3 (alpha)' 모델을 발표했다. 이 모델은 단순한 음성 합성을 넘어 실제 배우처럼 감정을 연기하고, 문장 중간에 톤을 전환하며, 등장인물을 바꾸는 기능을 갖추고 있다. 이러한 기술은 속삭임, 웃음소리, 숨소리, 박수 등 다양한 비언어적 요소를 실제 음성과 구분하기 어려울 정도로 자연스럽게 표현한다.

새로운 아키텍처 기반의 Eleven v3는 기존 모델보다 세부적인 지시가 필요하지만 그만큼 뛰어난 성능을 제공하며, 70개 이상의 언어를 지원하여 전 세계 인구의 90%를 커버할 수 있다. 이는 콘텐츠 제작자와 기업들이 오디오북, 캐릭터 대화, 인터랙티브 미디어 등에서 더욱 정교한 음성 표현을 가능케 한다.
Eleven v3의 주요 발전 사항으로는 대화 모드에서 화자 전환 및 감정 흐름의 자연스러운 처리가 있으며, 텍스트에 속삭임, 웃음, 아이러니한 톤 등 지시를 추가해 현장감을 높이는 음성 태그 지원이 특징이다. 또한, 한 문장 내에서도 감정과 속도 변화를 자유롭게 표현할 수 있어 다양한 콘텐츠에 활용 가능하다.
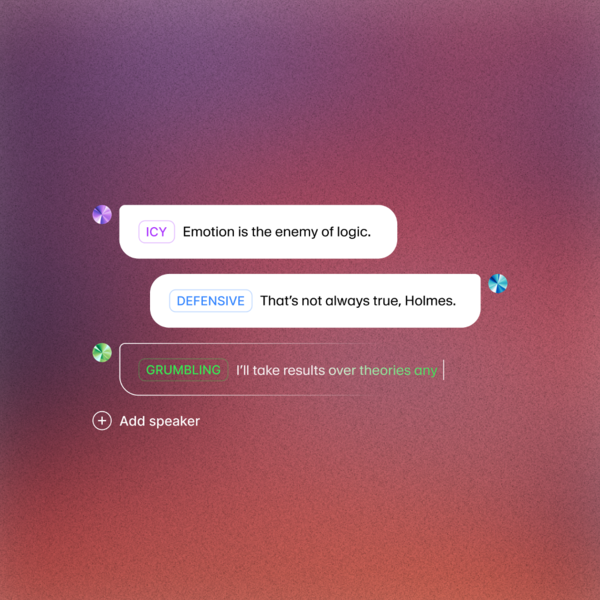
ElevenLabs의 공동창업자 겸 CEO Mati Staniszewski는 이번 모델이 감정과 표현, 비언어적 지시까지 이해하고 제어할 수 있는 가장 표현력 뛰어난 TTS 모델로서, 글로벌 미션에 부합하는 확장을 이루어냈다고 밝혔다. 특히 한국어 TTS 기능이 대폭 강화되어, 사투리와 같은 특별한 요청도 자연스럽게 표현할 수 있게 되었다. 이는 정부 기관, 지방 자치단체의 정보 전달부터 개인 크리에이터 콘텐츠까지 다양한 표현 가능성을 넓힐 것이다.
Copyright ⓒ 센머니 무단 전재 및 재배포 금지
본 콘텐츠는 뉴스픽 파트너스에서 공유된 콘텐츠입니다.



