[엠투데이 이정근기자] AI 컴퓨팅 기술 분야의 선두주자인 엔비디아가 엔비디아 지포스(NVIDIA GeForce) RTX GPU와 쿠다(CUDA) 12.8을 통해 로컬 거대 언어 모델(large language model, LLM) 실행 도구인 ‘LM 스튜디오(LM Studio)’의 성능을 향상했다고 밝혔다. 이번 업데이트로 모델 로드와 응답 시간이 크게 개선됐다.
문서 요약에서 맞춤형 소프트웨어 에이전트에 이르기까지 AI 사용 사례가 계속 확장되고 있다. 이에 따라 개발자와 AI 애호가들은 LLM을 더 빠르고 유연하게 실행할 수 있는 방법을 찾고 있다.
엔비디아 지포스 RTX GPU가 탑재된 PC에서 로컬로 모델을 실행하면 고성능 추론, 향상된 데이터 프라이버시, AI 배포와 통합에 대한 완전한 제어가 가능하다. 무료로 체험할 수 있는 LM 스튜디오와 같은 도구는 이러한 로컬 AI 실행을 간편하게 구현할 수 있도록 지원한다. 이를 통해 사용자는 자신의 하드웨어에서 LLM을 탐색하고 구축할 수 있다.
LM 스튜디오는 로컬 LLM 추론을 위해 가장 널리 채택된 도구 중 하나로 자리 잡았다. 고성능 llama.cpp 런타임을 기반으로 구축된 이 애플리케이션은 모델을 완전히 오프라인에서 실행할 수 있도록 한다. 또한 사용자 지정 워크플로우에 통합하기 위해 오픈AI(OpenAI) 호환 API(application programming interface) 엔드포인트 역할도 수행할 수 있다.
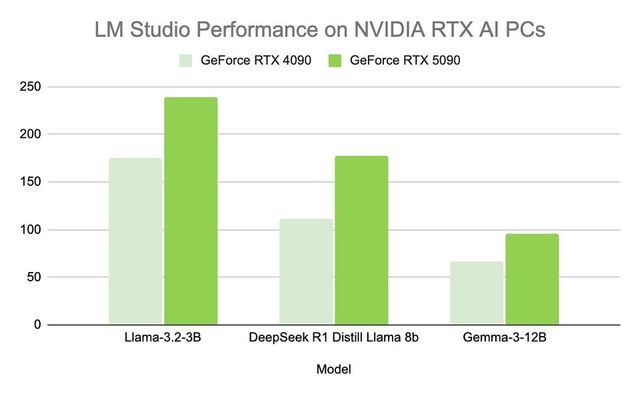
LM 스튜디오 0.3.15 버전은 쿠다 12.8을 통해 RTX GPU에서 성능이 향상되면서 모델 로드와 응답 시간이 크게 개선됐다. 또한 이번 업데이트에는 ‘툴_초이스(tool_choice)’ 파라미터를 통한 도구 활용 개선, 시스템 프롬프트 편집기 재설계 등 개발자 중심의 새로운 기능도 추가됐다.
LM 스튜디오의 최신 개선 사항은 성능과 사용성을 향상시켜 RTX AI PC에서 역대 최고 수준의 처리량을 제공한다. 즉, 더 빠른 응답, 더 신속한 상호작용, 그리고 로컬에서 AI를 구축하고 통합하기 위한 더 나은 툴을 제공한다.
Copyright ⓒ M투데이 무단 전재 및 재배포 금지
본 콘텐츠는 뉴스픽 파트너스에서 공유된 콘텐츠입니다.



