
o1이 처음 수능수학을 풀기시작했을때 모두가 환호했어요
LLM도 추론을 할수있고 한계를 벗어던졌고 사람 뛰어넘는건 시간문제고
근데 R1 o3 나오면서 뭔가 이상한게 보여요
답은 맞는데 풀이는 헛소리하고있는경우가 있다는거에요
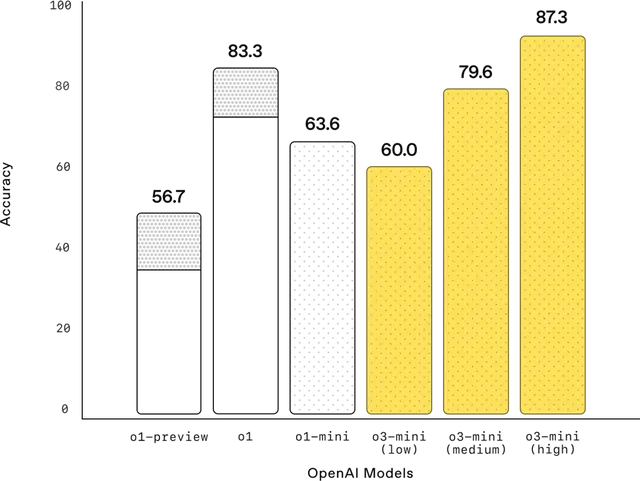
(AIME_24 벤치)
AI에게 수학을 가르치거나 평가할때는 가장 간단하면서도 확실한 방법을 써요: [문제 - 숫자로 된 답]을 주고 답을 맞추게 하거나 맞추는지 평가하기
함정은 AI가 "수학을 하는 법" 보다는 "답을 맞추는 법"을 배웠다는 거에요
이건 수학적 엄밀함이 결여된 일종의 패턴 매칭이라고 볼 수 있어요
답을 맞췄는지만 평가하는 AIME, FrontierMath만 보면 어지간한 프로 수학자만큼의 능력을 보여주는 것 같지만 아직도 수능 정답률 100%가 안나오고 USAMO, Putnam등 풀이과정까지 보는 벤치는 떡락하는 원인
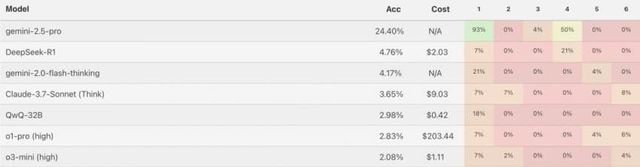
"패턴 매칭이더라도 풀 수 있고 정답률이 높으면 무의미한건 아니지 않느냐?" 라고 할수 있어요
물론 "답을 검증하는" 문제는 "답을 찾는" 문제보다 쉽기때문에 무의미하지야 않지만
AI가 항상 검사가 필요한 뛰어난 학생 정도에 머무르고 연구에 기여하지 못한다는 건 AGI니 특이점이니 하는거에 치명적이에요
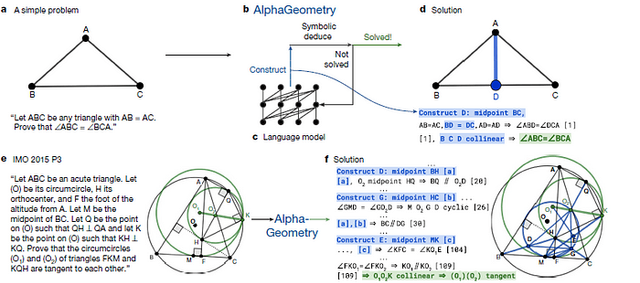
성과가 없는건 아니에요
AlphaProof와 AlphaGeometry는 IMO를 어느정도 정복했고
오픈소스 진영에서도 DeepSeek-Prover를 선두로 증명 문제를 신뢰 가능하게 푸는 데 나름 진전을 보였어요
여기서 "신뢰 가능하게"라는건 컴퓨터의 증명 검증 시스템을 사용해서
프로 수학자들의 동료평가보다도 맏을만해서 일단 나오면 검토할 필요도없이 발표할수있는 수준이에요
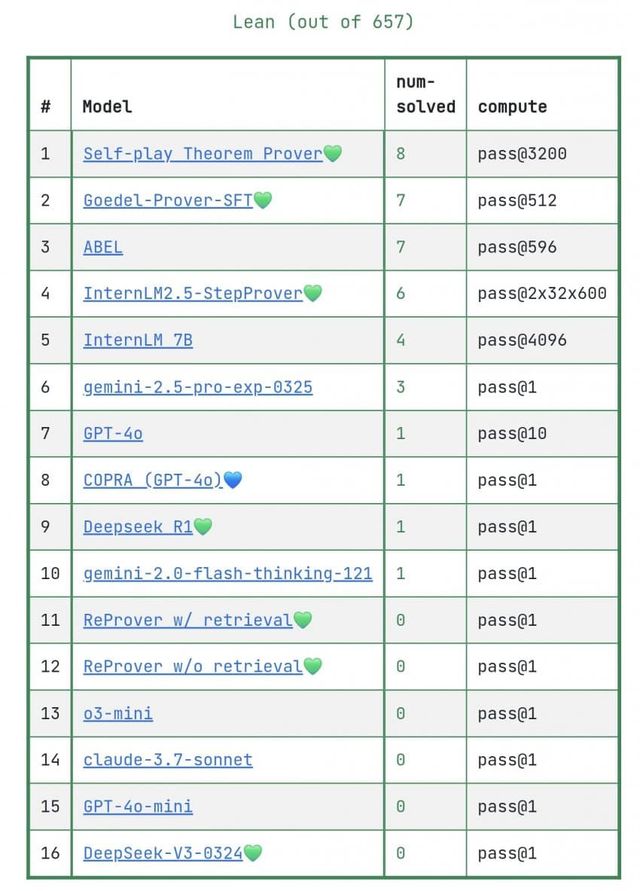
나쁜소식은 그 성과가 이정도밖에 안된다는거에요
다행히도 이 병목이 어디에서 일어나는지도 알고있어요
증명언어 데이터셋은 한줌수준도 아니고 티끌만도 못해서 자연어 증명언어 전환에서 손실이 많이나는거에요
RL을 진즉 도입했는데도 이렇긴하지만 일단 넘어가기로해요

테렌스 타오 등을 필두로 수학을 위한 AI 펀딩도 진행되었어요
충분한 투자가 이루어진다면 수년 내에 수학 연구 패러다임에 변화를 일으킬 인공지능 시스템을 기대할 수 있을가에요
Copyright ⓒ 시보드 무단 전재 및 재배포 금지
본 콘텐츠는 뉴스픽 파트너스에서 공유된 콘텐츠입니다.
다음 내용이 궁금하다면?
광고 보고 계속 읽기
원치 않을 경우 뒤로가기를 눌러주세요



