(대전=연합뉴스) 김준호 기자 = 비싼 데이터센터 그래픽처리장치(GPU)를 덜 쓰고, 주변에 있는 저렴한 GPU를 활용해 인공지능(AI) 서비스를 더 싸게 제공할 수 있는 기술이 개발됐다.
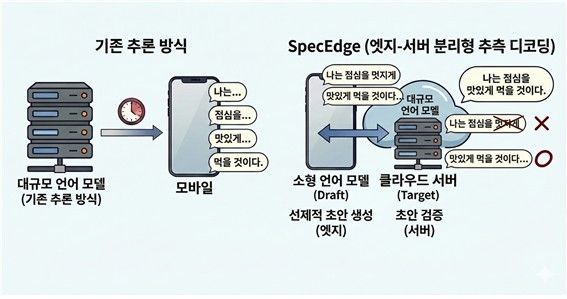
한국과학기술원(KAIST)은 전기및전자공학부 한동수 교수 연구팀이 데이터센터 밖에 널리 보급된 저렴한 소비자급 GPU를 활용해 대형 언어모델(LLM) 인프라 비용을 낮출 수 있는 새로운 기술 '스펙엣지'(SpecEdge)를 개발했다고 28일 밝혔다.
이 기술은 데이터센터 GPU와 개인 PC나 소형 서버 등에 탑재된 '엣지 GPU'가 역할을 나눠 LLM 추론 인프라를 함께 구성하는 방식이다. 이 기술을 적용한 결과, 기존 데이터센터 GPU만 사용하는 방식에 비해 토큰(AI가 문장을 만들어내는 최소 단위)당 비용을 약 67.6% 절감할 수 있었다고 연구팀은 설명했다.
데이터센터 GPU에서만 수행하는 방식과 비교해 비용 효율성은 1.91배, 서버 처리량은 2.22배 향상됐다. 일반적인 인터넷 속도에서도 문제없이 작동해 별도의 특수한 네트워크 환경 없이도 실제 서비스에 바로 적용할 수 있는 기술임을 확인했다고 연구팀은 덧붙였다.
이번 연구는 데이터센터에 집중돼 있던 LLM 연산을 엣지로 분산시켜 AI 서비스의 기반이 되는 인프라 비용은 줄이고 접근성은 높일 새로운 가능성을 제시했다.
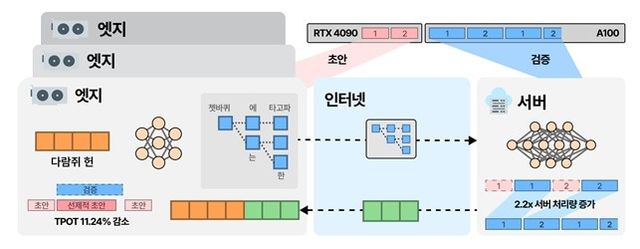
향후 스마트폰, 개인용 컴퓨터, 신경망 처리장치(NPU) 등 다양한 엣지 기기로 확장될 경우 고품질 AI 서비스가 보다 많은 사용자에게 제공될 수 있을 것으로 기대된다.
한동수 교수는 "데이터센터를 넘어 사용자의 주변에 있는 엣지 자원까지 LLM 인프라로 활용하는 것이 목표"라며 "이를 통해 AI 서비스 제공 비용을 낮추고, 누구나 고품질 AI를 활용할 수 있는 환경을 만들고자 한다"고 말했다.
이번 연구 결과는 최근 미국 샌디에이고에서 열린 AI 분야 최고 권위 국제 학회인 신경정보처리시스템 학회(NeurIPS)에서 스포트라이트(Spotlight)(상위 3.2% 논문, 채택률 24.52%)로 발표됐다.
kjunho@yna.co.kr
Copyright ⓒ 연합뉴스 무단 전재 및 재배포 금지
본 콘텐츠는 뉴스픽 파트너스에서 공유된 콘텐츠입니다.



