VAE (Variational AutoEncoder)
이전 시간에는 오토인코더에 대해 알아보았고, 오토인코더의 아쉬운 점 - 더 공간을 효과적으로 모아주고, 틈이 없게끔 모아서 어디에서 뽑건 의미있는 결과가 나오면 좋겠다 - 라는 점을 생각해보았다.
그 목표를 위해서 오토인코더에 분포(Variation)개념을 넣은 것이 VAE 이다. 이름을 보면 알겠지만 평범한 오토인코더에 확률 분포라는 개념이 가미된 형태이다.
+ AE 를 만들 때에는
- 입력값이 잠재공간의 한 점으로 대응되지만
+ VAE 를 만들 때에는
- 입력값이 잠재공간 상의 어떤 좌표 (mean) 를 중심으로하고 분산 (variance) 만큼 퍼져있는 분포로 대응된다
- 즉 한 점이라는 한개의 벡터값 대신
- 위치(mean)과 퍼진정도(variance)라는 두개의 벡터로 확장한 형태를 학습하게 된다
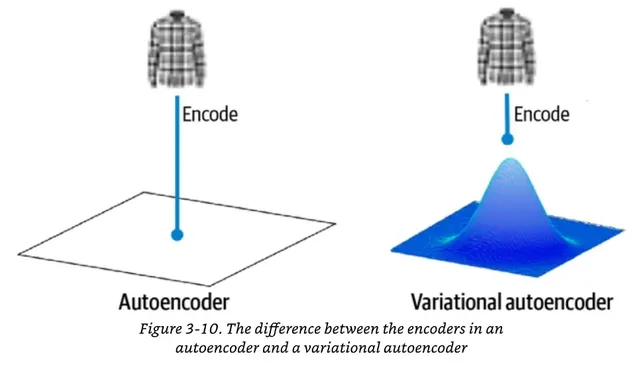
이렇게 하면 좋은 점이 뭘까?
- 우선 공간 안에 틈이 없이 메우기 좋다. 즉 공간에 연속성이 좋아진다. 예를 들어서 오토인코더 구조에서는 (-2, 2) 라는 좌표에서 어떤 그림이 찍혀나왔다고 하더라도, 거기에서 약간 떨어진 부분 (-2.1, 2.1) 에서는 아까와 비슷한 그림이 나올거라는 보장이 없지만 VAE에서는 그게 훨씬 좋다.
- 또한 VAE 는 AE 대비 잠재공간의 분포가 정규분포와 유사하게 만들어진다. 이렇게 하면 새로운 이미지를 생성할 때 성공률이 높아진다. 내가 찍은 공간이 정규분포에 속해있다면 어디를 찍어도 의미있는 이미지가 나올 가능성이 높다.
학습을 어떻게 시켜야 하나?
- 기존의 레이어를 변경해서 2개의 파라메터를 학습시키도록 변경하는데, 여기서 Reparameterization Trick 이란 기법을 써서 식의 형태를 약간 변형시킨다
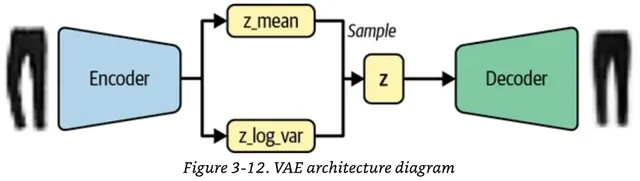
파라메터의 형태를 조절하는 이유는 모델의 학습과정에서 역전파가 좀 더 원활하게 작동하게 하는데에 목적이 있다.
- VAE 의 경우에는 샘플링을 할 때 중점과 분포값을 각각 랜덤 뽑기를 하는 대신, epsilon 이라는 한개의 값을 정규분포에서 뽑은 다음 그걸 이전 레이어에서 넘어온 중점과 분포값과 조합하는 방식이다.
- 역전파 과정에서는 두개의 변수가 하나로 합쳐지는 지점에서 편미분을 각각 계산하게 되는데, 랜덤요소가 양쪽에 있지 않고 한쪽에 몰려있는 쪽이 훨씬 잘 동작한다.
* 학습은 항상 추론의 반대방향으로 계산의 흐름이 만들어지는데, 그것들을 위한 편미분 계산, 자동 미분등은 keras 나 pytorch 같은 라이브러리가 알아서 해준다. 모델을 만드는 사람이 신경쓰는 것은 양쪽 방향 모두 그래디언트가 소실되거나, 폭발하거나, 수렴되지 못하고 국소지점에 머무는 일이 발생하지 않도록 매끄러운 방향을 만들어주는 것이 중요하다
+ 이런걸 어떻게 만드느냐.. 수준은 전문 연구자들의 영역이니까 우리는 그런게 있다는 것정도만 알고 넘어가자
레이어의 구조와 함께 학습의 핵심요소는 Loss 를 어떻게 정의하느냐이다
- 이전에 오토인코더에서는 높은차원의 원본 이미지를 인코더를 거치면서 낮은 차원을 통과시키면서 핵심 요소만 남겨낸 다음에 디코더를 통과하면서 다시 뿔려내면서 결과값을 만들고 그걸 처음의 원본과 얼마나 비슷한가 (reconstruction loss)를 계산했었다
- VAE 에서는 그 정보에 더해서 생성된 결과물이 최대한 정규분포에 가깝게 모일 수 있도록 추가적인 항목을 더해준다.
* 두개의 확률 분포가 얼마나 가까운가, 동떨어져있는가를 계산하는 방법으로 대표적인 것이 KL 발산 이라는 것이다
* KL 발산에 대한 자세한 설명은 이쪽을 참고하자
KL Divergence 에서 특기할만한 점
- 차이가 아니라 발산이다. 발산의 계산은 순서에 따라 달라진다. A분포를 기준으로 B 분포가 얼마나 발산하는가를 계산한 값과 B 분포를 기준으로 A 분포가 얼마나 발산하는가를 계산한 값은 같지 않다.
- VAE에서는 최종 결과물에서 계산된 위치와 분포값이 정규분포로부터 너무 벗어나면 loss 가 늘어나게끔 구성한다
- VAE Loss = 원본 이미지와 결과 이미지의 차이점 (reconstruction loss) + 결과 이미지가 정규분포에서 얼마나 발산했는지 정도 (KL Divergence loss)
- 즉, VAE에서 만든 결과는 정규분포의 범위쪽으로 모이게끔 유도된다. 결과적으로 새롭게 결과를 만들때 샘플링하기 좋아진다. 정규분포 안에서 하나 찍기만 하면 그럴듯한 결과가 나오는 보장이 AE 에 비해 VAE 가 훨씬 높다

- VAE 로 학습한 샘플들 사이에 있는 공간의 점을 찍으면 자연스럽게 그 중간 부분에 있는 모양이 찍혀나오게 된다. 굿!
- 그리고 잠재공간의 형태도 정규분포에 가깝도록 KL 발산항에 의해서 유도되었기 때문에 (멀어질 수록 페널티를 줌) 원점에서 일정한 거리 안에 있는 모양이 나온다. 정규분포는 중점이 0, 발산이 1 인 분포니까
+ 그래서 VAE는 본격적인 생성모델의 시작이다
스테이블 디퓨전에서 VAE 라는 단어 많이 들어봤는데?
- 스테이블 디퓨전 이전에도 dall-e 나 imagen 같이 텍스트에서 이미지를 뽑는 모델들이 있었는데
- 얘네들은 각 픽셀에 대해 연산을 하느라 모델이 무겁고 소비자급 GPU에서 동작할 수 없었다
- 512*512 픽셀 전체를 생성 대상으로 하지 말고
- 64*64 정도의 작은 공간으로 줄여서 생성을 하고, 생성된 결과는 나중에 해상도 불리기를 해서 만들면 어떨까? 라는 발상으로 만들어진 것이 스테이브 디퓨전이다
- 엄밀하게 말하자면 64*64 의 데이타는 우리가 생각하는 픽셀데이타와는 똑같지 않은 형태의 latent 공간상의 embedding 이다
* 디퓨전 그림찍는 과정에서 중간 중간 프리뷰로 나오는 이미지는 생성된 임베딩을 한번 디코딩 과정을 거쳐서 낮은 해상도의 비트맵 이미지로 변환시킨 것을 표현한 것임
- 즉, 스테이블 디퓨전에서 VAE는 해상도를 뿔려주는 역할을 한다
- 64*64 공간을 512*512 의 픽셀로 업스케일링하는 것을 생각하면 64:1 의 상당한 압축비를 보여주는데, 이게 가능한 이유는 애초에 VAE 는 비슷한 근사값을 만들기만 하면 되기 때문에 손실압축의 형태로 동작하기 때문
* 이런 원리들을 이용해서 구글 포토나 유투브등에서 쓰는 고압축 코덱을 개발하기도 했다
* 비슷하게 보기 좋으면 된거 아님?
이제 본격적인 생성의 손맛을 더 알아보자
- 너무 간단한 Fashion MNIST 대신 사람 얼굴이 들어있는 CelebA 데이타셋을 갖고 학습시켜보자

- VAE 모델을 이용해서 학습을 시키고 나면 아래와 같이 원본에 대해 비슷하게 이미지를 재구성하는 능력을 모델이 획득하게 된다

VAE는 생성형 모델이기 때문에 단순히 원래 이미지를 따라하는 것 뿐만 아니라 적절한 샘플링을 통해 새로운 이미지를 생성하는 것도 가능하다

요 데이타셋에는 이미지가 이십만장 넘게 들어있는데, 특기할만한 점으로는 각 이미지마다 특징에 대한 라벨 정보가 들어있다는 점이다
* 코의 뾰족함, 앞머리, 계란형 얼굴, 수염, 표정 (웃기), 모자 착용 유무, 안경 착용 유무 등등등
- VAE 는 비지도 학습이기 때문에 학습 과정에서 이러한 라벨 정보를 쓰는 일은 없다. 그런데 VAE 학습을 하고 나서 잠재공간상의 벡터들을 보면 특정 라벨정보 매칭되는 것들을 발견할 수 있다
* 즉, 웃는 얼굴이라는 라벨을 붙여놓은 것들을 잠재공간상에서 찾아보면 서로 가깝게 몰려 있고, 수염난 얼굴, 안경, 앞머리, 모자 등도 마찬가지로 서로 모여서 의미있는 엠베딩을 만들게 된다!
+ 학습을 한 예제를 살펴보면
- 약간 뿌옇게 되는 단점은 있지만, 원본 데이타를 비슷하게 재생성하는 것이 가능하다는 것을 확인할 수 있고
- 잠재공간의 임베딩 벡터들을 뽑아서 각 차원별로 분포를 확인해보면, 각 차원별로 벡터의 성분이 서로 독립적으로 정규분포를 띄고 있다
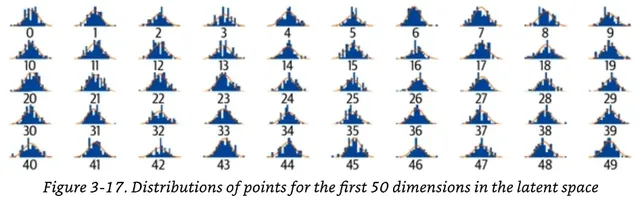
- 즉 쏠림없이 잘 분포된 엠베딩을 확보했다면 n차원 정규분포 안에서 뽑기를 하는 것만으로도 새로운 얼굴을 만들 수 있고
- 특질벡터 (Feature Vector) 라는 개념을 이용해서 원하는 방향으로 샘플링 유도도 가능하다
* 웃는 얼굴이라는 특질 벡터가 몇번째 차원인지 알아냈다면 생성시 샘플링을 할 때 거기에 특성벡터를 더해주는 것만으로 결과물에 더 웃는 모습을 부여해줄 수 있다
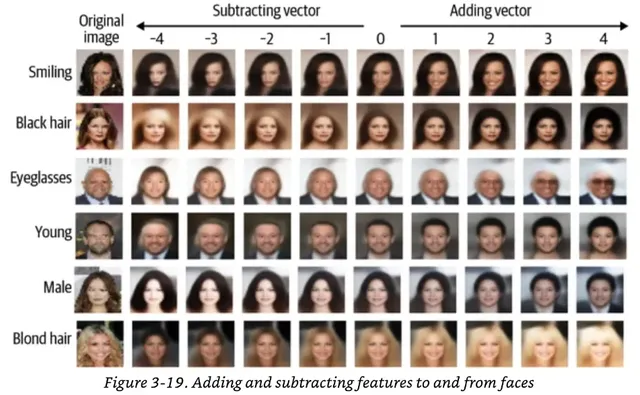
- 연속성이 있으니까 샘플링한 두 점 사이를 보간하면서 디코딩을 하는 것으로 이미지 모핑도 쉽게 가능하다

정리
+ VAE 를 통해서 본격적인 생성 AI 의 원리를 확인해보았다.
- 단순히 압축률 좋게 원본 데이타셋을 모델에 압축하는 것에 그치지 않고, 공통적인 특질을 학습해서, 그걸 원하는대로 재조합해서 생성할 수 있다.
Copyright ⓒ 시보드 무단 전재 및 재배포 금지
본 콘텐츠는 뉴스픽 파트너스에서 공유된 콘텐츠입니다.
다음 내용이 궁금하다면?
광고 보고 계속 읽기
원치 않을 경우 뒤로가기를 눌러주세요



