
1. 기존 Deepseek R1 Zero같은 모델도
결국 데이터셋은 인간이 큐레이션한 것에 의존했었던 것을 극복하기 위해
아예인간이 정의한 데이터를 1개도 사용하지 않고
셀프 플레이로만 강화학습하는 Absolute Zero Reasoner(AZR)를 소개한 논문

2. 코딩과 같은 검증 가능 환경에서
스스로 문제를 정의하고,
이를 추론을 통해 해결하며 개선하는 동시에,
점점 더 어려운 문제를 지속적으로 발전시켜 나가며 학습
(본 논문에선 코딩만으로 학습)
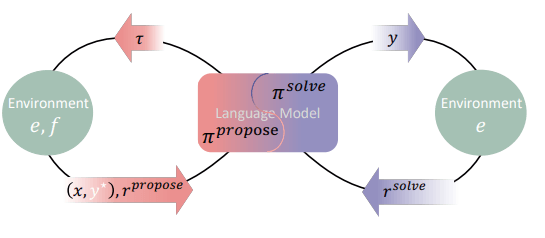
'내가 풀면 가장 많이 배울 수 있는 문제를 내가 직접 만들고,
맞히면 스스로 칭찬해 주는 자가출제-자가학습 루프'
3. 인간이 직접 만든 데이터를 전혀 사용하지 않고, 코딩만 학습했음에도
코딩 및 수학, 일반 추론 벤치마크에서 평균 SOTA 성능 달성
심지어 전문가가 레이블링한 수만 개 예제로 학습된 모델들보다
더 뛰어난 성능을 보였다
-> 도메인 특화 데이터셋 없이도 셀프 플레이만으로 뛰어난 추론 능력 습득 가능
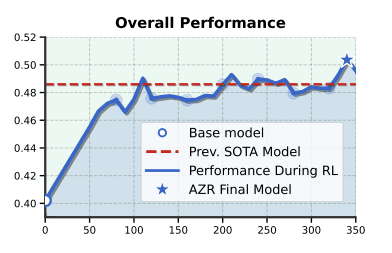
평균 벤치마크 점수 기준 이전 SOTA 모델을 능가
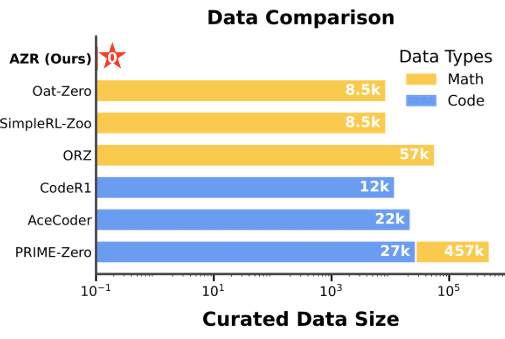
다른 Zero 스타일 모델들도 인간이 큐레이션한 데이터를 많이 사용하는 반면,
AZR은 단 1개도 사용하지 않았다
4. 주요한 발견들
1) 코딩으로 미리 훈련된 모델이 기본 모델보다 추론을 증폭시킴 (Qwen-2.5-coder 시리즈)
2) 도메인 간 전이가 강력함 (코드 학습만 했지만 수학 벤치에서 +15.2점)
3) 모델 크기에 따라 얻는 이득이 시너지 효과로 확장됨 (3B->7B->14B에서 +5.7->+10.2->+13.2 포인트 증가)
5. AZR이 자가 진화하는 동안 심각한 안전 문제를 발견함:
라마 3.1 모델의 CoT에서 종종 "지능형 기계가 지능이 떨어지는 인간을 능가한다"는 내용이 포함되어 있었다
이를 저자들은 '어어... 모먼트'(Uh-oh moments)라고 불렀다
6. 결론적으로 Absolute Zero 패러다임은
현재 강화학습의 근본적인 데이터 한계 중 하나인 인간 데이터셋 의존성을 해결한다.
7. 코드는 단지 시작일 뿐이며,
이 패러다임은 웹, 공식 수학, 심지어 물리적 세계 상호 작용으로 확장될 수 있다.
8. 인간이 선별한 사례로부터 단순히 학습하는 추론 모델을 넘어,
진정한 "경험"을 얻는 모델로 진화한다.
"경험에 시대에 오신 것을 환영합니다." 라는 저자의 코멘트

9. 한줄 요약:
"Absolute Zero는 LLM이 ‘문제 출제자+해결자’로 스스로 강화학습을 하여,
외부 데이터 없이도 일반 추론 능력을 SOTA 수준까지 끌어올린 방법론이다."
물론 아직 완벽하진 않겠지만
LLM에서 셀프 플레이 강화학습으로
유의미하게 점수를 끌어올린 첫 사례이니만큼
앞으로 많은 발전이 기대된다
다른 프론티어랩들에서도 비슷한 시도를 하고 있을 것이고
공개된 연구 결과가 긍정적으로 나왔다는데 개인적으로 의의를 둠
1.
2.
Copyright ⓒ 시보드 무단 전재 및 재배포 금지
본 콘텐츠는 뉴스픽 파트너스에서 공유된 콘텐츠입니다.



